In this collaboration with researchers from the Umeå University and the University of Zurich, Renaud Lambiotte from Oxford Mathematics explores the use of higher-order networks to analyse complex data.
"Network science provides powerful analytical and computational methods to describe the behaviour of complex systems. From a networks viewpoint, the system is seen as a collection of elements interacting through pairwise connections. Canonical examples include social networks, neuronal networks or the Web. Importantly, elements often interact directly with a relatively small number of other elements, while they may influence large parts of the system indirectly via chains of direct interactions. In other words, networks allow for a sparse architecture together with global connectivity. Compared with mean-field approaches, network models often have greater explanatory power because they account for the non-random topologies of real-life systems. However, new forms of high-dimensional and time-resolved data have now also shed light on the limitations of these models.
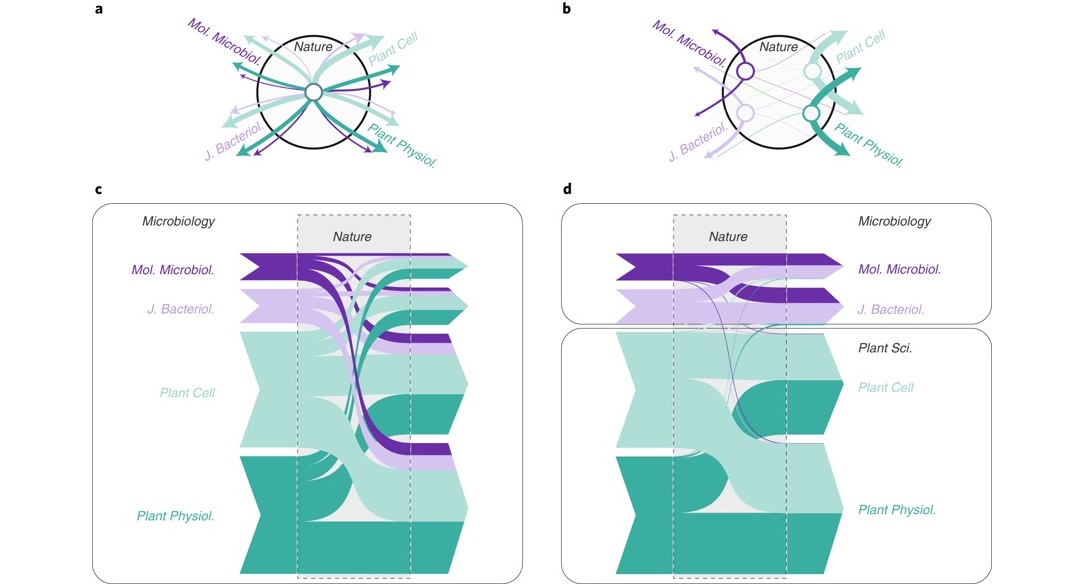
Rich data indicate who interacts with whom, but also what different types of interactions exist, when and in which order they occur, and whether interactions involve pairs or larger sets of nodes. In other words, they provide us with information on higher-order dependencies, which lay beyond the reach of models based on pairwise links. In this perspective published in Nature Physics, the authors review recent advances in the development of higher-order network models, which account for different types of higher-order dependencies in complex data. They focus in detail on models where chains of interactions are more than a combination of links, and when higher-order Markov models are required to reproduce realistic chains. As an illustration, the Figure shows (click to enlarge) chains of citations between journals as produced by standard network models (left) versus empirical data and higher-order models (right). As a next step, the authors illustrate how to generalise fundamental network science methods, namely community detection, node ranking and the modelling of dynamical processes. They conclude by discussing challenges in developing optimal higher-order models that take advantage of rich data on higher-order dependencies while avoiding the risk of overfitting."