Community Structure in Product-Purchase Networks
![]()
- Researcher: Roxana Pamfil
- Academic Supervisors: Sam Howison and Mason Porter (UCLA)
- Industrial Supervisors: Rosie Prior and Shreena Patel
Background
With the introduction of store loyalty cards in recent decades, there has been an ever-growing body of data on shopping habits and preferences. Despite this rich data, understanding and predicting consumer behaviour remains a difficult problem. This is due to the myriad of factors that affect consumers' decisions (anything from mood to current weather), the inherent incompleteness of the data (as customers may frequent more than one supermarket chain), and the ever-changing needs and habits of customers (such as increased preference for healthier foods).
A network model of shopping activity consists of customers connected to products that they previously purchased. It is common to add weights to these edges to indicate frequency of purchase. Densely connected clusters or "communities" in these networks reveal customers with similar preferences and the products that they buy the most. The goal of this project is to devise suitable community-detection algorithms for these networks. Once customers and products are partitioned in this way, one can fill in "missing links" within communities to recommend new products to customers.
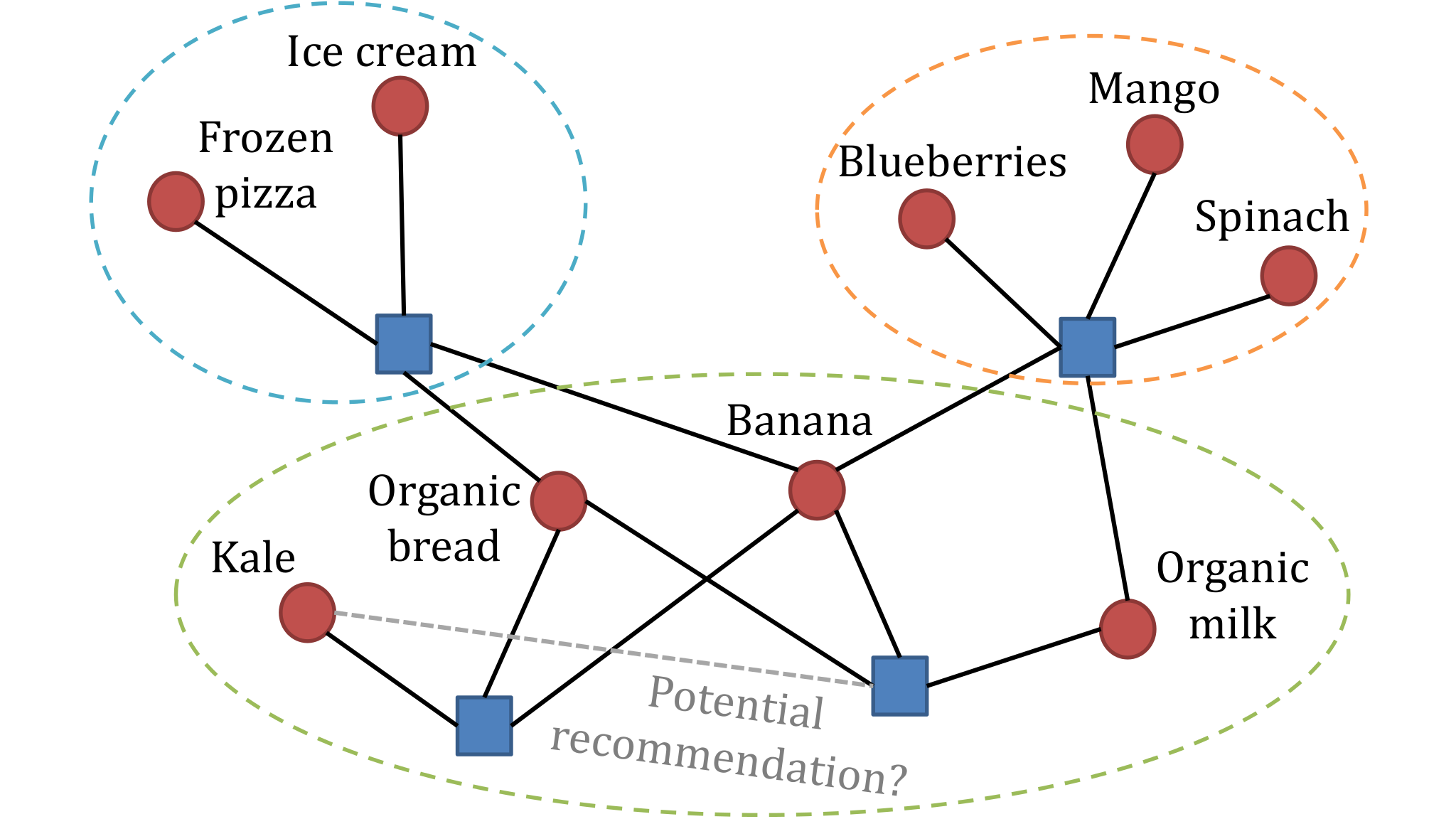
Figure 1: Schematic of a product-purchase network with three communities.
Outcomes
In our work, we have considered several network representations beyond the most basic one. Three examples are annotated networks, temporal networks, and multilevel networks.
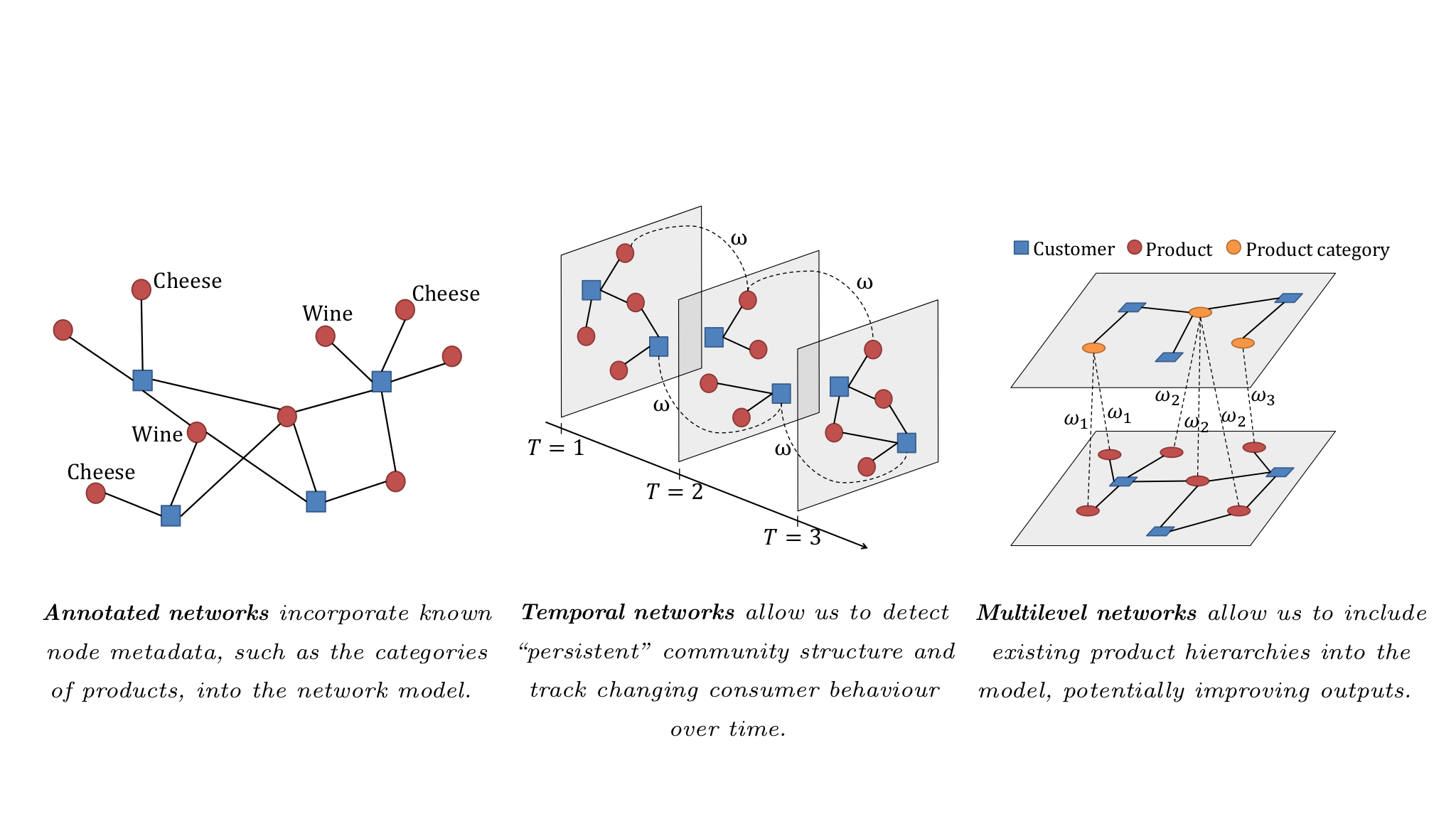
Figure 2: We have studied community detection for different network representations relevant to consumer behaviour applications.
Annotated networks include some additional labels on the nodes; for our application, we label each product with the product category that it belongs to. These annotations give prior probabilities for products to belong to different communities. We found that this approach leads to improved results, as it reduces the uncertainty around the correct community membership of product nodes. An additional benefit is that the underlying statistical model allows stores to predict which customers would be most interested in a new product before it even appears on a shelf, just by looking at the category of that product.
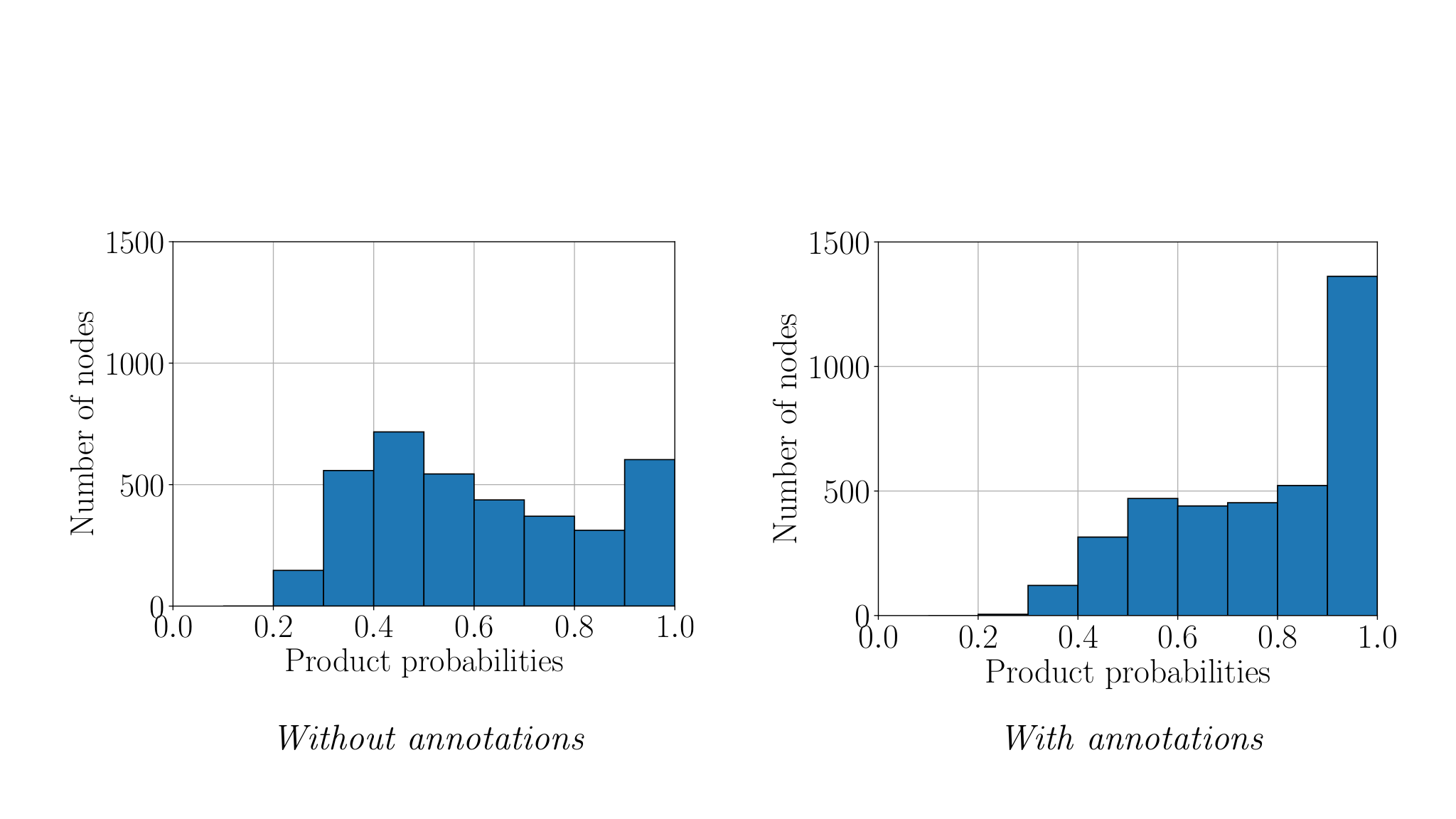
Figure 3: These histograms show, for all product nodes, the extent to which they belong to their best community (expressed as a probability). Left: Without annotations, there is significant uncertainty as the model assigns many products with just 30–60% probability to their best community. Right: with annotations, these probabilities get skewed towards 1.
Because consumer preferences evolve constantly, a significant part of our work has been to develop methods that reveal changes in the structure of temporal networks. This approach helps uncover seasonal shopping patterns (e.g. turkey in the winter, Pimm's and strawberries in the summer), as well as more lasting changes in consumer preference (e.g. gluten-free options, health-conscious eating). Detecting communities in such "multilayer" networks is very much still an open problem. One popular method is to maximise a generalised version of an objective function known as modularity. Writing down multilayer modularity requires the specification of two types of resolution parameters, and choosing these appropriately is crucial for uncovering meaningful community structure in networks. One of our key results in this area is a method for inferring these parameter values in a principled way [1].
In multilevel networks, the layers define a hierarchy of single-layer networks. Outside the realm of consumer behaviour, an example would be collaboration networks between researchers (lowest level), departments (intermediate level), and universities (highest level). For product-purchase networks, multilevel representations provide a way to incorporate existing product hierarchies into the network structure. This is useful because the correct level of aggregation when constructing networks from transaction data is often not obvious from the start: should loose bananas be considered the same product as packed bananas, or should they be kept as separate nodes in the network? Adapting some of the methodology that we developed for temporal networks, we propose a community-detection algorithm for multilevel networks.
Our final contribution incorporates "edge correlation" in models of multilayer networks. For shopping networks, we expect there to be significant correlation between what a customer buys today and what they buy a few months from now, and these features are not being adequately captured by existing models. This work has implications not just for consumer behaviour and recommender systems, but also in fields like biology, where aggregating different (correlated) data sources is important for overcoming the high level of noise that is present in the data.
We are currently in the process of harnessing these models to identify relevant product recommendations for customers. We aim to test the quality of these recommendations by using historical data and, potentially, by sending coupons to customers to elicit their interest in those products.
Publications
[1] Pamfil, A.R., Howison, S.D., Lambiotte, R. and Porter, M.A.. Relating modularity maximization and stochastic block models in multilayer networks. arXiv preprint arXiv:1804.01964 (2018).