Arrival Management for Systemised Airspace
- Researcher: Lingyi Yang,
- Academic Supervisors: Samuel Cohen and Jaroslav Fowkes
- Industrial Supervisors: Richard Cannon, Adrian Clark, Preetam Heeramum and George Koudis
NATS
Background
We rely on air traffic controllers to ensure the safety and punctuality of our flights. One bottleneck to the amount of air traffic that can be processed is runway availability. Heathrow is the 12th busiest airport in the world and has only two runways, making it the busiest two runway operation in the world. In Figure 1, we see the actual radar tracks of flights arriving to London. The clusters, indicated by the rings of colours in Figure 1, are queues which flights join until they are cleared for landing.
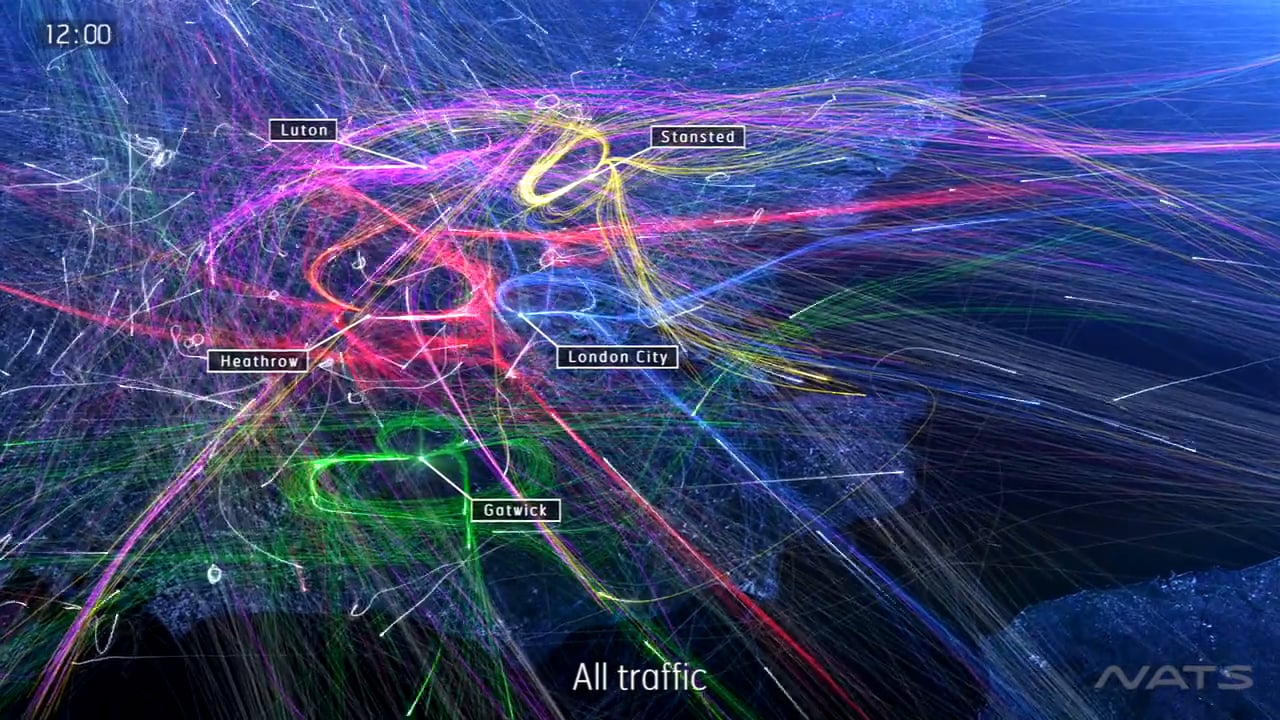
Figure 1. Visualisation of flight paths above London.
The planes waiting in the queues are not necessarily cleared to land on a first-come-first-served basis. This is because the minimum separation distances between consecutive aircraft are based upon their sizes. Larger, heavier aircraft cause more disturbance in the air therefore a longer gap has to be left before allowing another aircraft to pass through the region. This phenomenon, known as wake vortex formation, can have serious safety implications. The time between successive arrivals can be minimised if flights are arranged into blocks of aircraft of the same size.
Queues provide controllers buffer time to arrange arrivals so that the runway can be better utilised. However, queues also contribute to delays and excess fuel consumption, both of which have financial and environmental impacts.
The research question I am addressing is: can we give instructions to planes further in advance so that they arrive in a sequenced manner and can land almost immediately without circling in stacks. Our aim is to design a system to recommend such actions to controllers.
Progress
We use reinforcement learning methods by modelling the air traffic controller as an agent that observes the number of aircraft and where they are, then sends out speed instructions. The environment encapsulates the dynamics of the planes in the system. If an aircraft lands safely without violating minimum separation distance then our agent gains a positive reward. See the reinforcement learning schematic in Figure 2. Through repeated simulations the agent can learn how to act so that the maximum reward is obtained in various situations, without additional human input. The mapping between states to actions is called the policy.
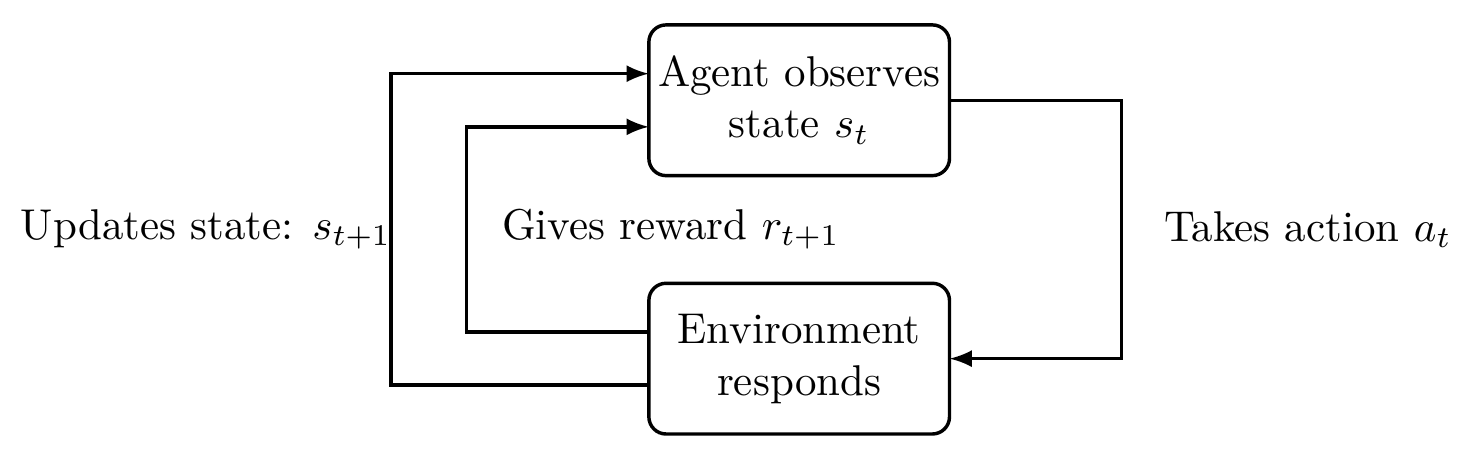
Figure 2. Schematic of reinforcement learning.
There are also some practical constraints to be considered. Since cataloguing all possible scenarios is computationally prohibitive, we have to find a reduced representation of our model, similar to the way we compress photos as JPEGs to reduce their file size. This is known as function approximation. Neural networks are nonlinear function approximators and we use them to represent the states of our problem, this is known as deep reinforcement learning. We extract geometric features of the flight paths to reduce dimension further by using path signatures.
We see in Figure 3 that using a deep reinforcement learning method called DDPG results in faster improvements compared with classical reinforcement learning methods Q-Learning and SARSA. As we increase the precision of our model, the classical methods become infeasible due to the computational costs but these results indicate good approximate solutions can be found.
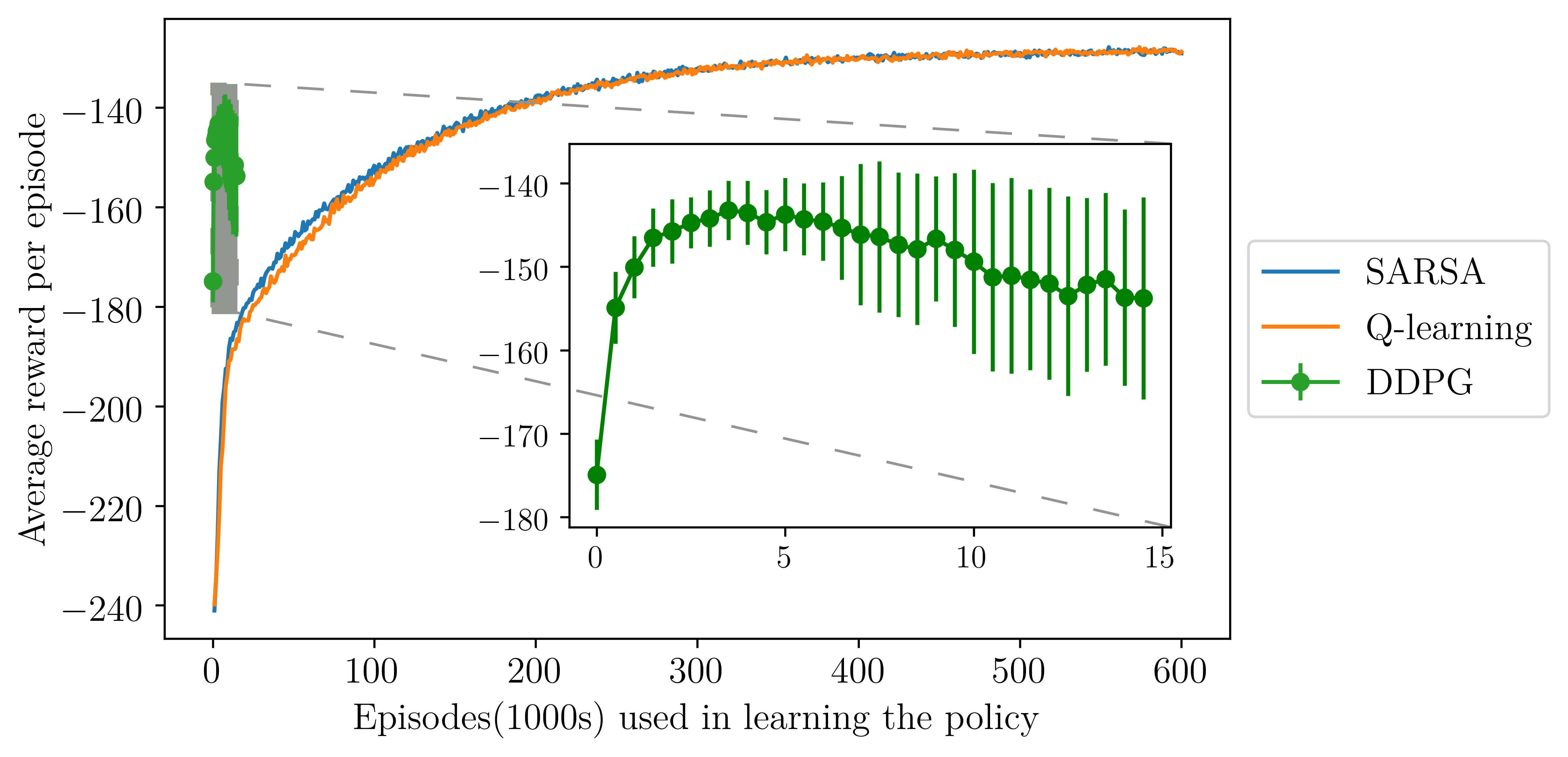
Figure 3. Average reward per episode as the policy is learnt using exact representations with SARSA and Q-learning, and using neural networks in DDPG.
Future Work
Classical methods are guaranteed to find the best strategy. By using neural networks, we lose this guarantee and may choose a locally optimal strategy instead. More research is needed to determine if a sensible solution can always be found when using neural networks.
Since we have also made many simplifications, we also have to develop the model so that it is a more physically realistic model. We are also exploring ways in which we can obtain faster convergence as we scale up the model.